

Bare så det er sagt – dette er viktig, men kanskje nerdete. Nå er det sagt, og jeg håper du likevel velger å lese videre. Jeg skal prøve å forklare dette så godt som jeg kan.
Det første jeg vil si er at en praterobot og en språkmodell ikke er det samme. Prateroboten er det programmet du bruker til å kommunisere med en språkmodell, og språkmodellen er bare ett av mange elementer i prateroboten. Det er praterobooten som bestemmer hva som skal hentes fra dokumenter og Internett på beskjed fra språkmodellen, og hvordan svaret fra språkmodellen skal vises til deg til slutt. Dette har jeg samlet i denne figuren («Algoritme» er i praksis et program som ofter bruker en språkmodell til deler av jobben):
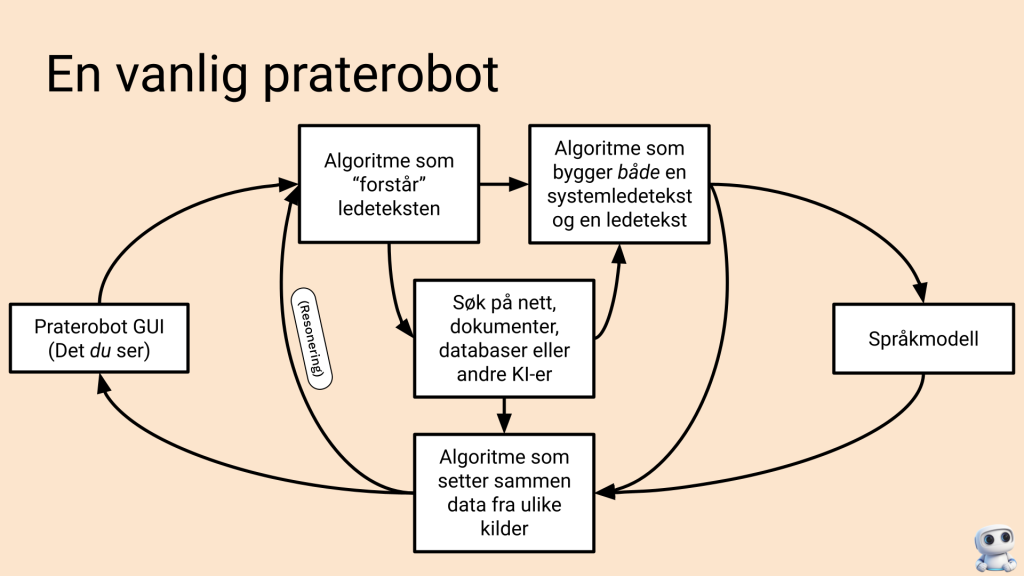
I figuren over står det derimot ingenting om den sentrale funksjonen til et kontekstvindu. Så… et kontekstvindu er den mengden tekst (informasjon/kontekst) som en språkmodell kan jobbe med på en gang. Hver gang prateroboten sender en «prat» til en språkmodell sender den en pakke med informasjon (tekst, bilder, lyd osv) til språkmodellen. Denne pakken kan bare være opp til en viss størrelse, oppgitt i tokens. Du kan regne et token som en slags stavelse, så en tekst på 100 ord har rundt 150 tokens – alt etter om et språk har lange ord eller ikke. Bibelen er rundt 1M tokens – bare for å gi en ide om hvor mye tekst 1 million tokens er. I tabellen under har du en oversikt over hvor mange tokens dagens språkmodeller kan arbeide med i en slik pakke.
| Språkmodell, informasjonsgrense og kontekstvindu |
| OpenAI gpt-5.4-mini (aug-25) – 400K gpt-5.4 (aug-25) – 1M gpt-5.5 (des-25) – 1M |
| Google Gemini 3.1 Flash-Lite (jan-25) – 1M Gemini 3.5 Flash (jan-25) – 1M Gemini 3.1 Pro (jan-25) – 1M |
| Anthropic Claude Haiku 4.5 (jul-25) – 200K Claude Sonnet 5 (jan-26) – 1M Claude Opus 4.8 (jan-26) – 1M |
Det vi mennesker ikke så lett forstår er at informasjon som ikke ligger i denne pakken ikke eksisterer for språkmodellen! Sagt på en annen måte – om du laster opp 10 store dokumenter i en praterobot kombinert med en lang samtale, så kan det blir mer enn kontekstvinduet språkmodellen kan jobbe med. Da må prateroboten kutte ut noe før den sender pakken til språkmodellen. Kanskje tar den bare med deler av dokumentene – altså at den kjører en RAG-rutine som plukker ut det prateroboten antar er de viktige delene av dokumentet. Kanskje oppsummerer prateroboten begynnelsen av den lange samtalen, slik at den ikke tar så mye plass. Kanskje kutter den ut noen av de store dokumentene. Uansett – prateroboten må kutte noe, og den forteller deg ikke hva den kutter eller skriver om. Husk at det som kuttes ikke eksisterer for språkmodellen, selv om det var med i en pakke tidligere. Det er bare det som blir sendt, når det blir sendt, som eksisterer når språkmodellen jobber med pakken.
Vi mennesker jobber helt annerledes enn en språkmodell. Du blir bedt om å lese en trilogi, og så oppsummere bok nummer to. Da vil du gjøre oppsummeringen vel vitende om at du har lest bok en og tre, og du husker dem sånn omtrentlig. Oppsummeringen din vil derfor ta hensyn til at du har lest de to andre bøkene, og det kan hende at du løfter frem helt andre momenter i oppsummeringen enn om du ikke hadde lest dem.
Så laster du opp alle tre bøkene til en praterobot, og ber den oppsummere bok to. Prateroboten skjønner at den ikke har plass til mer enn bok to i kontekstvinduet og legger derfor bare med bok to i pakken som går til språkmodellen. Språkmodellen aner ikke at det finnes en bok en og en bok tre, og heller ikke hva som står i dem. Ser du hva som skjer nå? Oppsummeringen blir gjort bare ut fra hva som står i bok to, og blir kontekstløs i forhold til den oppsummeringen et menneske vil gjøre.
Nå kan det hende du sier at – ja, men dagens KI-en har jo enorme kontekstvinduer. Du har jo plass til hele Bibelen i en pakke! Og det er riktig… på papiret.
Det er likevel ikke det som skjer i prateroboten. De ulike leverandørene gir deg nemlig ikke tilgang til hele kontekstvinduet! Det er for dyrt. Jo større kontekstvinduet er, jo mer datakraft må KI-en bruke på å lage et svar. Vil du vite hva du egentlig får lov til å bruke av kontekstvindu i de forskjellige praterobotene? Dette er det jeg har funnet ut fra ulike kilder. De ulike leverandørene av prateroboter har ofte ikke lyst til å skrive så mye om det, fordi dette er noe de endrer ofte – alt etter om det er stor belastning på systemene deres eller ikke.
| Praterobot og kontekstvindu |
| Microsoft Copilot Gratisutgaven gir deg ikke mer enn 4K-8K. Copilot Chat, som er den utgaven som er i den vanlige M365, er på 64K-128K. |
| OpenAI ChatGPT I gpt-5.5 instant får du 16K i gratisutgaven, 32K i plus og 128K i pro. I gpt-5.5 thinking får du 256K i plus og 400K i pro. |
| Google Gemini I gratisutgavene begrenses det til 32K. AI Plus, som er edu-utgavene, får du 128K. AI Pro og AI Ultra får du tilgang til 1M (her må du betale ekstra i måneden). |
| Anthropic Claude I Sonnet og Opus får du bruke 500K i de betalte abonnementene. I Claude Code får du bruker 1M for betalte abonnementer. Claude gjør ikke RAG av filer i den vanlige prateroboten. Enten laster den inn hele filen, eller så lager den et program som prøver å finne den aktuelle informasjonen den bør hente ut. I «Prosjekter» RAG-er den, men med informerte begrensninger. |
Her ser du at det er betraktelig større begrensninger enn hva KI-en faktisk får til, og dette får stor betydning for hva KI-en faktisk får jobbe med når du gir den en ledetekst. Da kan lett risikere at et sammendrag av en lang rapport, eller flere dokumenter, ikke blir et sammendrag der språkmodellen får se all tekst. Den får bare se deler av teksten, fordi det ikke er plass til alt i kontekstvinduet prateroboten gir deg tilgang til. Da vil sammendraget i utgangspunktet mangle noe, og du vet ikke hva!
Det eneste unntaket er faktisk Claude, som er helt ærlig med når kontekstvinduet er fullt og gir deg anledning til å bestemme hva den nå skal gjøre (eller sier at nå kan den ikke laste opp flere filer).
Så hvis du lurer på hvorfor prateroboter konfabulerer om kilder og påstander og meninger, så kan det godt være at akkurat den viktige teksten som ville forhindret feilen ikke kom med til språkmodellen. Da eksisterer ikke den informasjonen for språkmodellen, men det kan godt hende at den skriver noe den opplever naturlig å skrive til den teksten som faktisk kom med. Den eneste som kan sjekke dette er du som ba om svaret, og som må sjekke det og gå god for det. Hvis det er viktig at det prateroboten skriver stemmer, og du ikke er sikker, må du sjekke det et annet sted enn hos prateroboten. Du må kanskje gjøre jobben og lese ting selv.
Legg igjen en kommentar