
Bare for å sagt det med en gang – du er ikke dum om du ikke helt skjønner hva kontekstvindu og retrieval-augmentet generation (RAG) er og hva det gjør med dialogen din med prateroboten. Dette er ikke så enkelt å forstå som vi skulle tro, fordi en språkmodeller tenker så veldig annerledes enn det vi gjør – selv om det ser så gjenkjennelig ut. Vi begynner med kontekstvindu og så tar vi RAG etterpå, som en delvis løsning på noen utfordringer kontekstvinduer gir oss og som lager andre utfordringer.
En viktig ting i det jeg skriver videre – det er forskjell på hva en praterobot er og hva en språkmodell er. Prateroboten er programmet du bruker for å kommunisere med språkmodellen. ChatGPT er en praterobot og gpt-4o er en språkmodell. Det er to veldig forskjellige ting.
Et kontekstvindu
En språkmodell har en absolutt grense for hvor mye tekst den kan arbeide med på en gang. Dette kalles et kontekstvindu, og navnet er ikke tilfeldig. I et kontekstvindu ligger alt språkmodellen skal jobbe med, med systemledetekst og all tekst du gir den å jobbe med. En språkmodell vet ingenting om det den skal jobbe med utenom det som ligger i kontekstvinduet. Så hvis du har en dialog med en praterobot blir hele dialogen etter hver som den utvikler seg lagt ved, så det som legges i kontekstvinduet blir større og større. Hvis prateroboten ikke hadde gjort det hadde den glemt alt som dere snakket om tidligere i dialogen og bare svart på siste spørsmål som om det var det første spørsmålet. Så i kontekstvinduet ligger all kontekst som språkmodellen skal jobbe med. Det som ikke ligger i kontekstvinduet eksisterer ikke for språkmodellen. Språkmodeller husker ingenting. De bare jobber med teksten som er i kontekstvinduet. Det som var i det forrige kontekstvinduet de jobbet med er «glemt» når jobben er ferdig. Dette er en veldig fremmed tanke for oss mennesker, fordi vi husker ting etter hvert som vi gjør ting i verden.
Utfordringen kommer når språkmodeller har grenser for hvor stort dette kontekstvinduet kan være. Per dags dato har OpenAI GPT-modellene en grense på 128K tokens, altså alt fra 64K-90K ord alt etter hvor akademisk teksten er (hvor lange ord teksten bruker). Anthropic Claude-modellene har en grense på 200K tokens og Google Gemini-modellene på 2048K, så her er det store forskjeller på hvor mye tekst de ulike språkmodellene kan «se» på en gang. Husk at dette ikke sier noe om hvor stor en tekst du legger ved kan være, men det sier noe om totalen – altså systemledetekst + dialog + ny ledetekst + opplastede ting.
Hva gjør en praterobot hvis det som skal legges ved blir større enn kontekstvinduet til språkmodellen? Det er nå det blir spennende, og utfordrende. Prateroboten må gjøre noe med det den legger inn i kontekstvinduet som sendes til språkmodellen. På godt norsk, den må kutte ut tekst eller forkorte tekst. Og hva den gjør får du ikke vite! Det er her RAG-metodene kommer inn i bildet, så nå går vi over til hva RAG er.
Retrieval-Augmentet Generation (RAG)
RAG betyr egentlig bare at prateroboten selv legger ved tekst for å forbedre genereringen av tekst. Du har sikkert lært på et kurs om KI at jo mer kontekst (eller tekst) du gir en praterobot, jo bedre vil svaret bli. Prateroboter kan i dag selv finne tekst den mener er aktuell i forhold til det du har skrevet inn i ledeteksten, og så legge den til ledeteksten før den sender det til språkmodellen. Det finnes utrolig mange måter praterobotene gjør dette på, og her er tre vanlige måter – hvor bare den første egentlig er enkel å forstå.
Bestemt tekst blir lagt ved
Prateroboter kan legge ved bestemte tekster alt etter konteksten den står i. Dette kan være nettsiden du er inne på, eller andre ferdig definerte tekstblokker. Siden du er på nå har et slik eksempel på en slik RAG. Hvis du klikker på prateroboten nede høyre hjørne har den en ledetekst hvor all tekst på denne nettsiden er lagt ved i systemledeteksten. Så hvis du bruker denne prateroboten på en annen side på denne bloggen vil den aktuelle bloggteksten på siden automatisk legges inn i systemledeteksten. Da kan du ha en prat med prateroboten om innholdet på siden, uten at du må legge inn noe selv.
Hvis teksten på denne nettsiden ikke hadde vært lagt inn i systemledeteksten og blitt en del av kontekstvinduet, hadde språkmodellen ikke kunnet svare på hva denne siden handler om. Dette er noe SNL eller de ulike digitale læremidlene enkelt kunne lagt inn som en prateroboten på sine sider, og som det finnes ørten utvidelser av til nettlesere.
Søk på Internett er mer tekst
Dette er i praksis at en praterobot «velger» å søke på nettet etter tilleggsopplysninger, om språkmodellen gir beskjed om at den ikke mer særlig sikkerhet kan forutsi hva tekst den bør skrive. Hvis prateroboten støtter denne funksjonen vil den søke etter det den får tilbakemelding om hva språkmodellen, og så legger den ved tekst fra søket inn som tilleggstekst i ledeteksten før språkmodellen får lage sitt svar.
Hvis du for eksempel skriver «Hvem er Odin Nøsen?» som ledetekst, vil språkmodellen gi prateroboten beskjed om at den bør søker etter «Odin Nøsen». Prateroboten får teksten til venstre i bildet under som svar fra Google, legger det inn som en del av ledeteksten og så lager språkmodellen svaret til høyre. Legg merke til at prateroboten bare har lagt ved utdragene fra Google og ikke hentet tekst fra de ulike sidene Google viser til (og at den ignorerer teksten fra Twitter/X).
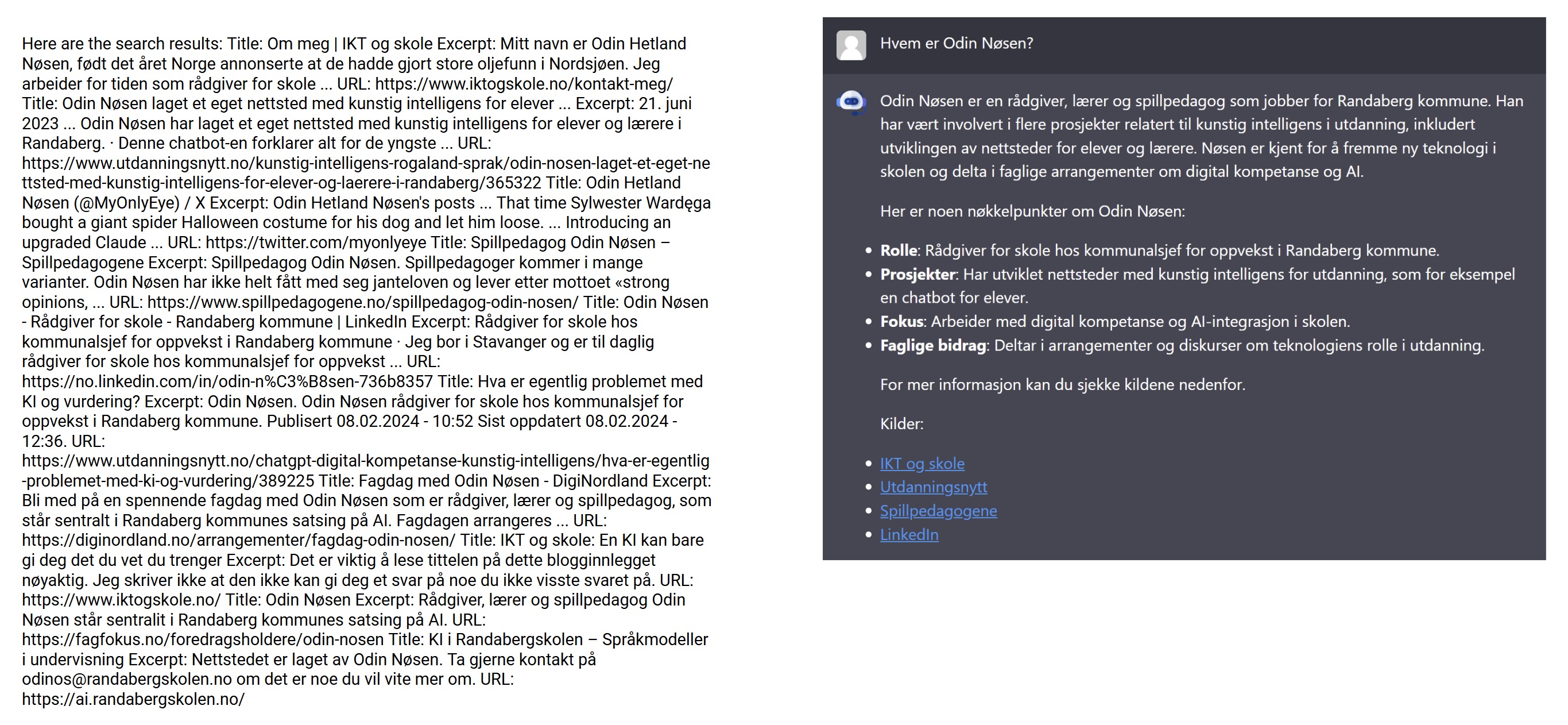
Svaret som blir produsert er uansett mye bedre enn det språkmodellen ville gitt som svar på spørsmålet uten at prateroboten hadde hentet mer tekst / kontekst fra Google. Husk at språkmodellen vet ingenting mer om Odin Nøsen enn det som står i teksten til venstre. Det den skriver til høyre er det den klarer å produserte av aktuell tekst ut fra konteksten i ledeteksten. Språkmodeller skriver så godt at den kan lure deg til å tro at den vet mer om det den har søkt etter enn den faktisk vet.
Noen prateroboter søker først på Google, og så på sidene Google viser til og så kanskje enda mer ut fra hva disse sidene igjen viser. Hvordan prateroboter løser dette er opp til programmeringen i selve prateroboten. Ikke glem at hvor mye tekst som kan legges ved fra nettet er begrenset av størrelsen på kontekstvinduet og hvor mye som må være med av andre opplysninger enn resultatet fra nettsøk, som dialogen frem til nå og systemledetekst.
Semantisk vektorsøk
Den tredje vanlige RAG-teknikken er det som kalles et semantisk vektorsøk i en tekst. Det er denne metoden som blir brukt når en praterobot ikke kan legge ved all tekst den ønsker i kontekstvinduet.
Et semantisk søk er et søk hvor du ikke søker etter like ord, men lik mening. Dette er også noe prateroboten gjør i samarbeid med språkmodellen. Du laster opp et dokument med tekst (en tekstfil, Word-dokument eller PDF). Prateroboten deler teksten opp i overlappende deler («chunks») og så får den en språkmodell til å knytte en vektor til hver av delene. Dette er en prosess som kalles «embedding».
En embedded vektor på en chunk er som et fingeravtrykk. Dette er en lang rekke med tall som representerer meningen og innholdet i teksten på en matematisk måte. Hvis vi har en chunk med teksten «Det var en gang en liten rev», vil en språkmodell konvertere denne teksten til en lang rekke tall, som for eksempel [-0.09, 0.26, -0.31…]. Da vil to tekster som handler om det samme få lignende tallverdier i vektorene sine, og vi kan søke gjennom mange vektorer for å finne chunks som ligner på hverandre. Dette gjør at vi kan finne relevant informasjon, selv når ordene ikke er like.
Det gjør at prateroboten kan gjøre semantiske søk etter de ulike delene av dokumentet, alt etter hva du skriver i ledeteksten. Det du skriver i ledeteksten gjøres alltid om til vektorer av språkmodellen og så søker prateroboten gjennom alle «chunkene» i dokumentet og gir dem en skår ut fra hvor samsvarende de er i mening med ledeteksten, ut fra vektorene. De delene som har høyest skår legges til ledeteksten før den sendes til språkmodellen. Du kan se de ulike stegene i denne prosessen i bildene under.





Men hvorfor ikke bare legge ved all tekst hvis det er så viktig å ha all tekst tilgjengelig? Vel, det er her kontekstvinduet kommer. Hvis du har et stort dokument, eller mange dokumenter, så får de ikke plass i kontekstvinduet. Da må prateroboten ha en funksjon for å plukke ut aktuelle deler av tekstsamlingen du har lastet opp til den. Det er dette semantiske vektorsøk kan være gode til. Da sikrer du at du får de mest meningssvarende delene av dokumentene lagt til ledeteksten ut fra det du spør om. Det er likevel tre utfordringer her. Du kan ikke styre denne prosessen, og du får ikke vite hva som blir lagt til – og ikke hva som ikke legges til heller! Du vet rett og slett ikke hva som egentlig ligger til grunn for det språkmodellen svarer.
Så i det du laster opp dokumenter til ChatGPT blir de bearbeidet slik at prateroboten kan gjøre semantiske søk i dem, for å plukke ut de tekstdelene språkmodellen mener passer best med ledeteksten du har gitt den. ChatGPT kan i tillegg søke på nettet etter informasjon, hvis språkmodellen gir beskjed om at den mangler kontekst. Alt dette legges inn i ledeteksten uten at du får vite hva som legges ved. Du får vite at den søker på nett, du får vite nettstedene og du får vite hvilke dokumenter den henter noe fra – men du får ikke vite hva den legger ved og hva den ikke legger ved. Så du kjenner ikke hele konteksten som språkmodellen bruker når den svarer.
Det er det siste der som er så vanskelig for oss mennesker å forholde oss til når det kommer til prateroboter og språkmodeller. Når vi har lest en tekst husker vi omtrentlig hva som står i den. Så når jeg leser kapittel 2 i en bok leser jeg det med konteksten at jeg har lest, og omtrentlig husker, kapittel 1. Hvis du gir hele boken til ChatGPT og ber den om å oppsummere kapittel 2, så gjør den ikke det slik jeg gjør det. Den kan ikke ha hele boken i kontekstvinduet og må velge ut deler. ChatGPT fyrer opp RAG-en, gjør noen semantiske søk etter hva den mener er de mest aktuelle delene av (forhåpentligvis) kapittel 2, og så får du en oppsummering. Du får ikke vite om prateroboten gikk glipp av det viktige avsnittet i dette kapittelet, og den har ingen mulighet til å lese kapittel 2 i lys av kapittel 1 – siden ingenting av kapittel 1 kommer til å legges ved i ledeteksten språkmodellen jobber med. Og hvis det ikke ligger ved i ledeteksten språkmodellen jobber med, så har den ingen ide om at denne teksten overhode eksisterer. Språkmodellen vet ikke hva den ikke vet.
RAG er både teknologisk spennende, nyttig og farlig. Nyttig, fordi du kan effektivt finne meningslik tekst og ikke bare like ord. Farlig, fordi du ikke vet hva språkmodellen ikke vet når den skriver, samtidig som den er så flink til å skrive kontekstuelt «korrekt» og kan gi skinn av at den vet noe den faktisk ikke vet. Det er så lett for oss mennesker å legge til vår kontekst i den språkmodeller skriver, fordi vi antar at teksten er skrevet av et annet tenkende vesen som tenker som oss. Noe den ikke er eller gjør.
Legg igjen en kommentar